Am 18. Mai 2026 fand im MG2/00.10 mit rund 15 Teilnehmenden eine 90-minütige Stakeholder-Sondierung zum BaKuLe-Baustein „Feedback App“ statt. Im Mittelpunkt stand evalchat – ein Prototyp, der versucht, Lehrevaluation als Dialog mit einem Sprachmodell zu führen statt als Fragebogen. Der Baustein „Feedback App“ startet im BaKuLe-Projekt regulär erst 2029. Was an diesem Vormittag herausgekommen ist, fließt jetzt in seine Ausgestaltung ein.
Der Bericht folgt grob dem Ablauf der Session – kurze Einordnung, Vorstellung des Prototyps, Befunde aus einem Begleitexperiment in der Vorlesung „Einführung in die Informatik“ – und ergänzt zwei Abschnitte, die in dieser Form vor Ort nicht möglich waren: eine Verdichtung der Diskussion und der Pad-Mitschrift sowie eine aggregierte Auswertung der Selbst-Evaluationen, die die Teilnehmenden im Hands-on-Block über das System selbst abgegeben haben.
Warum dialogisch?
Standardisierte Fragebögen sind effizient, aber sie passen schlecht zu dem, was Lehrende eigentlich brauchen. Die Response-Raten unserer EvaSys-Erhebungen liegen oft im einstelligen Prozentbereich, und das Material, das zurückkommt, ist meist generisch: „Vorlesung war okay“, „Mehr Übungsaufgaben wären gut“. Konkrete Hinweise, die zu echten Änderungen führen, sind selten. Studierende hätten durchaus etwas zu sagen; das Format erlaubt nur keine Nachfragen, nimmt keinen Kontext auf und wirkt schnell wie Pflichtkür ohne Adressaten.
Tutor-Gespräche wären besser, sind aber nicht skalierbar. Ein 15-Minuten-Gespräch produziert konkrete, durchdachte, kontextualisierte Rückmeldungen. Das Problem ist nicht die Qualität, sondern die Kosten: Für einen Kurs mit 250 Studierenden braucht man rund 60 Tutor-Stunden plus Organisation plus Schulung. Bei zwei Erhebungen pro Semester über die ganze Universität ist das undenkbar. Die offene Frage war: Geht das mit einem LLM gut genug, um die Skalierungslücke zu schließen?
evalchat in 5 Minuten
evalchat ist ein Chat-Bot, der mit Studierenden 15 bis 25 Minuten über einen Kurs spricht und am Ende eine editierbare Zusammenfassung erstellt. Studierende erhalten einen Einladungscode, landen auf einer Begrüßungsseite, chatten mit einem LLM (in unserer Konfiguration Claude), und bekommen am Schluss eine Markdown-Zusammenfassung angezeigt, die sie vor der Weitergabe an die Lehrenden bearbeiten, kürzen oder ablehnen können. Die Lehrenden sehen nur, was die Studierenden freigeben.
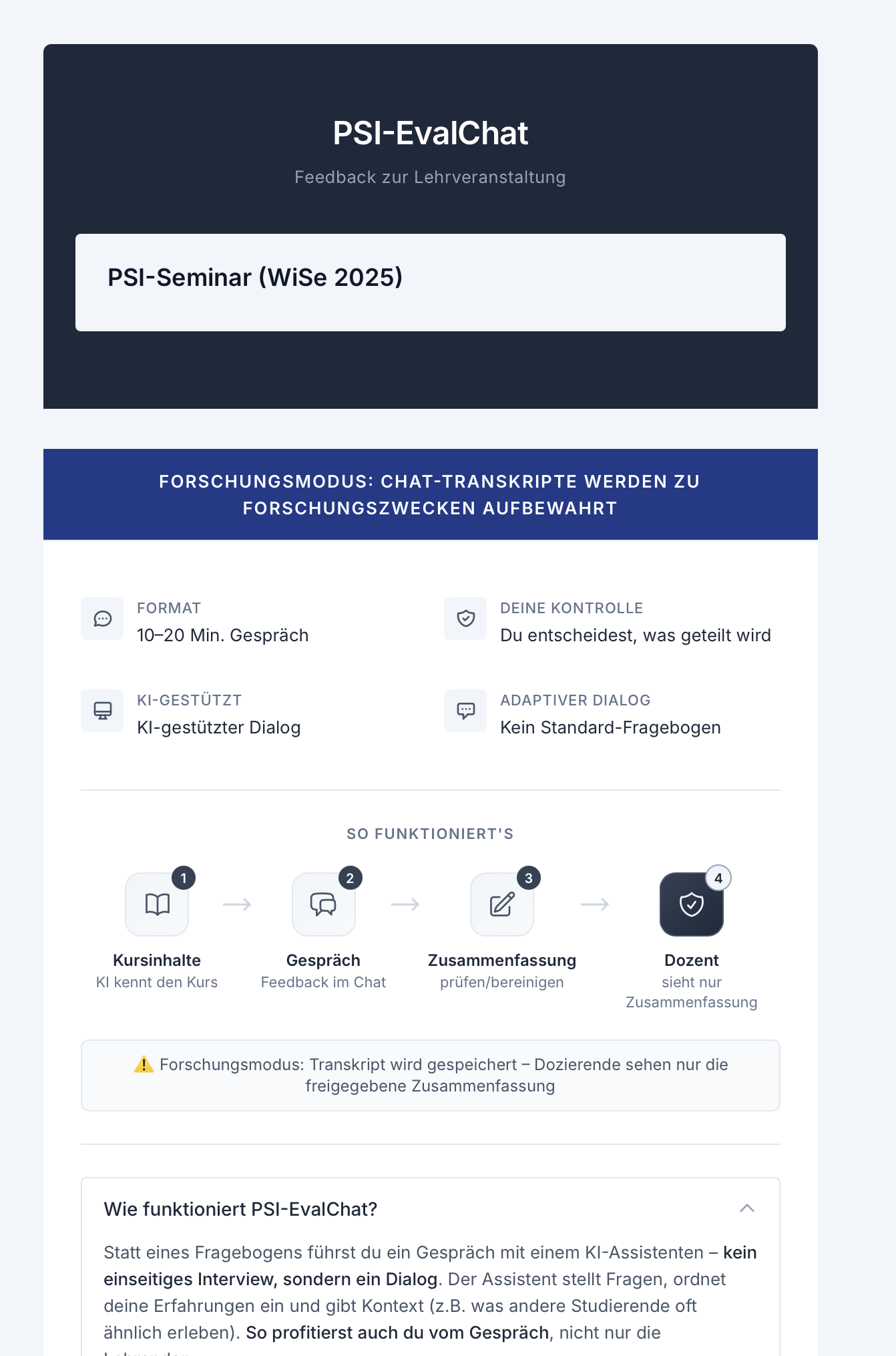 Vor dem Gespräch sehen Studierende eine Kurz-Erklärung des Formats, ein Vier-Schritte-Onboarding und einen sichtbaren Datenschutz-Hinweis. Im Forschungsmodus erscheint zusätzlich ein orangefarbener Banner.
Vor dem Gespräch sehen Studierende eine Kurz-Erklärung des Formats, ein Vier-Schritte-Onboarding und einen sichtbaren Datenschutz-Hinweis. Im Forschungsmodus erscheint zusätzlich ein orangefarbener Banner.
Zwei Mechanismen heben evalchat über einen Standard-Chatbot hinaus. Erstens: Ein zweites LLM beobachtet das Gespräch und gibt dem ersten Hinweise. Während das Haupt-LLM mit den Studierenden chattet, schaut ein Oversight-Modell parallel mit und schlägt situativ vor: jetzt Themenwechsel, jetzt nachfragen, jetzt mehr Agency geben, gleich aufs Ende zugehen. Das hält Gespräche im Fluss und verhindert sowohl Endlosschleifen als auch vorzeitiges Beenden. Zweitens: Kursspezifischer Kontext wird ins Gespräch eingewoben. Das Modell weiß, dass der Kurs eine Projektmesse hatte, dass Scratch der Einstieg war, dass die E-Prüfung in VS Code stattfand. Wenn jemand vage sagt „die Übungen waren okay“, kann das Modell konkret nachfragen: „Welche Übung war das – Caesar, Mario, Filter?“
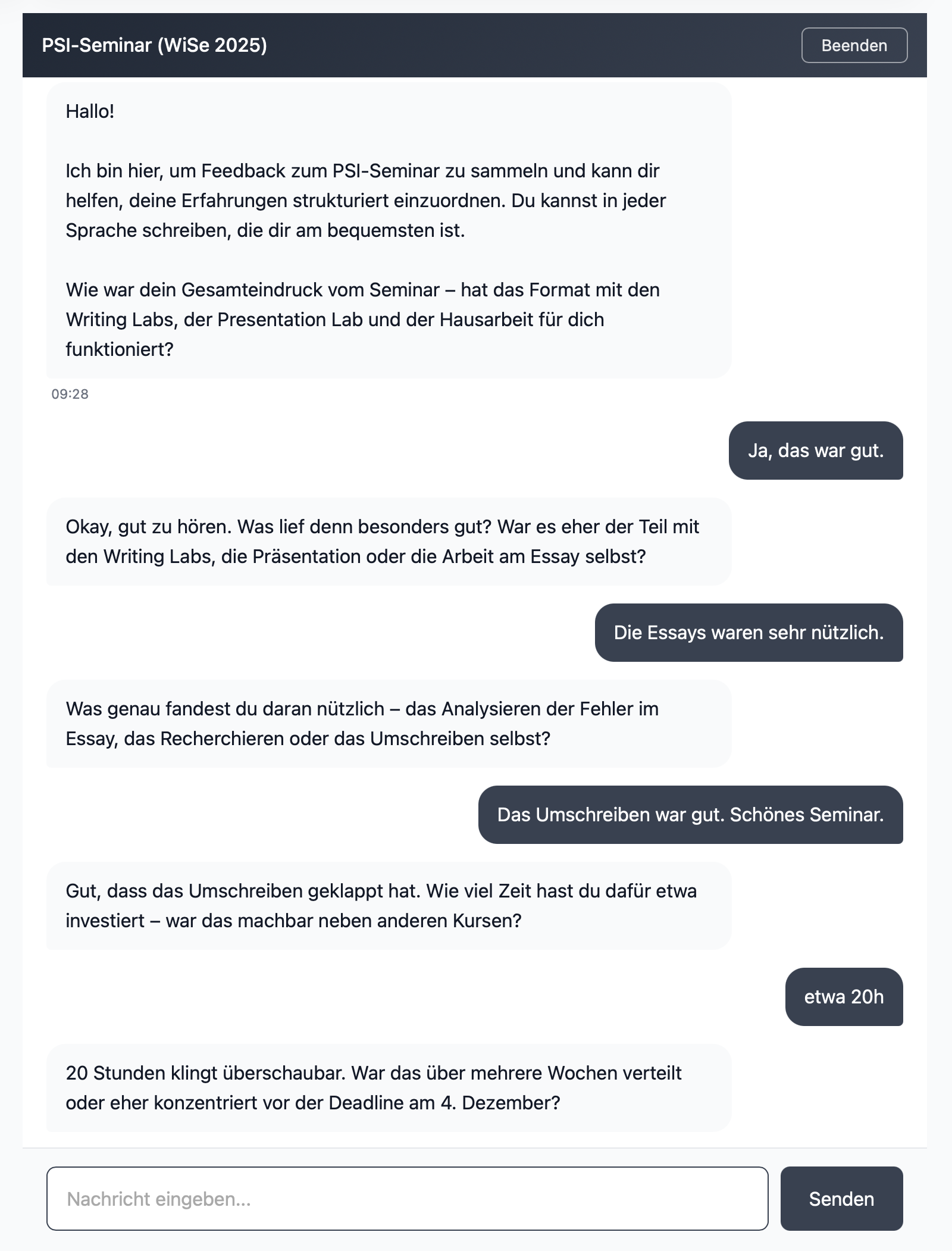 Der Bot eröffnet mit einer kurzen Selbstvorstellung und einer offenen Eröffnungsfrage, die – wenn Kurskontext vorliegt – die Bestandteile der Veranstaltung benennt. Studierende antworten in freier Sprache; der Bot greift Stichworte auf und vertieft nach.
Der Bot eröffnet mit einer kurzen Selbstvorstellung und einer offenen Eröffnungsfrage, die – wenn Kurskontext vorliegt – die Bestandteile der Veranstaltung benennt. Studierende antworten in freier Sprache; der Bot greift Stichworte auf und vertieft nach.
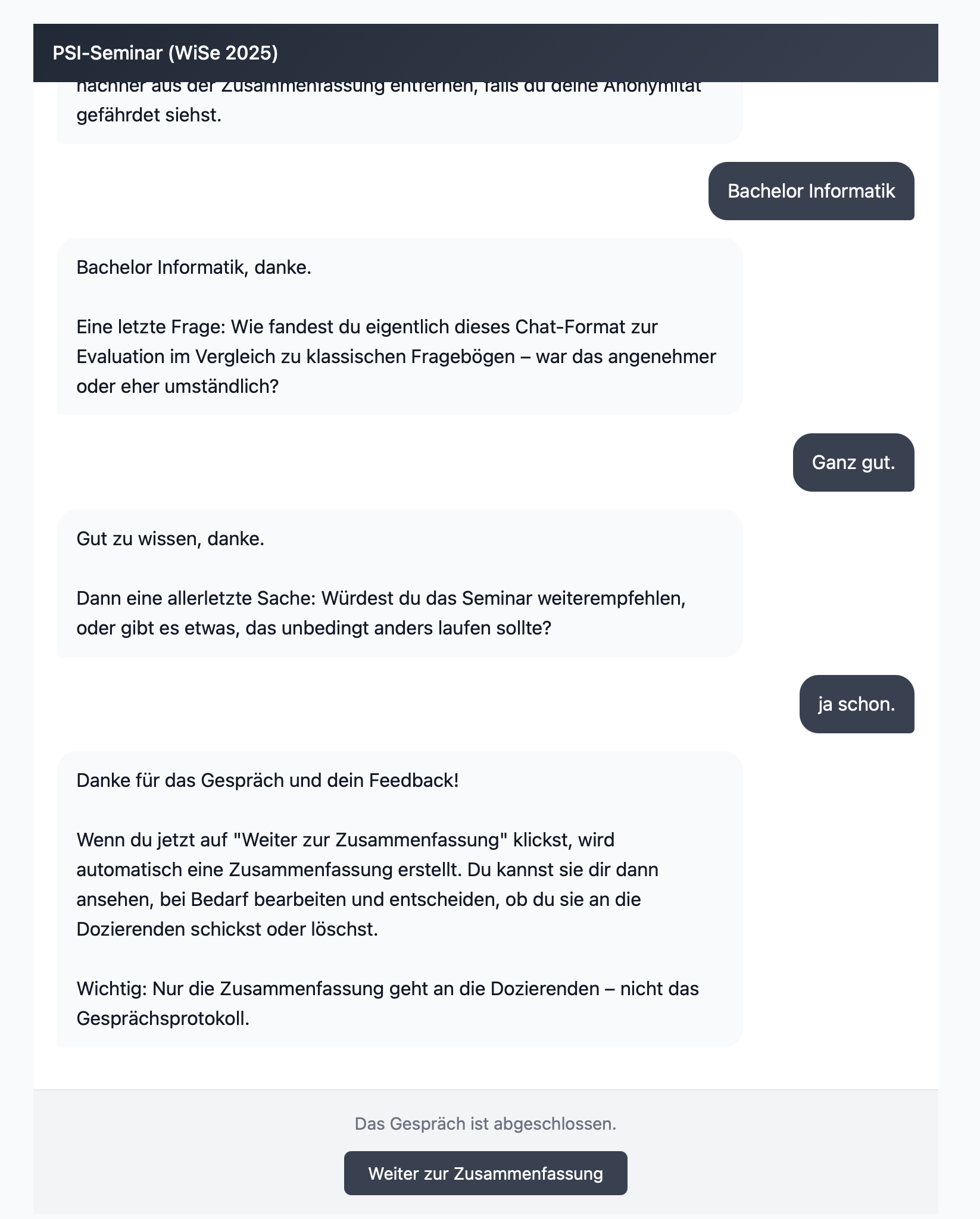 Vor dem Ende prüft der Bot kurz noch Eckdaten und erfragt eine Format-Reflexion sowie eine Weiterempfehlungs-Frage. Danach beendet er das Gespräch aktiv – kein Zeitdruck, aber auch keine Endlosschleife.
Vor dem Ende prüft der Bot kurz noch Eckdaten und erfragt eine Format-Reflexion sowie eine Weiterempfehlungs-Frage. Danach beendet er das Gespräch aktiv – kein Zeitdruck, aber auch keine Endlosschleife.
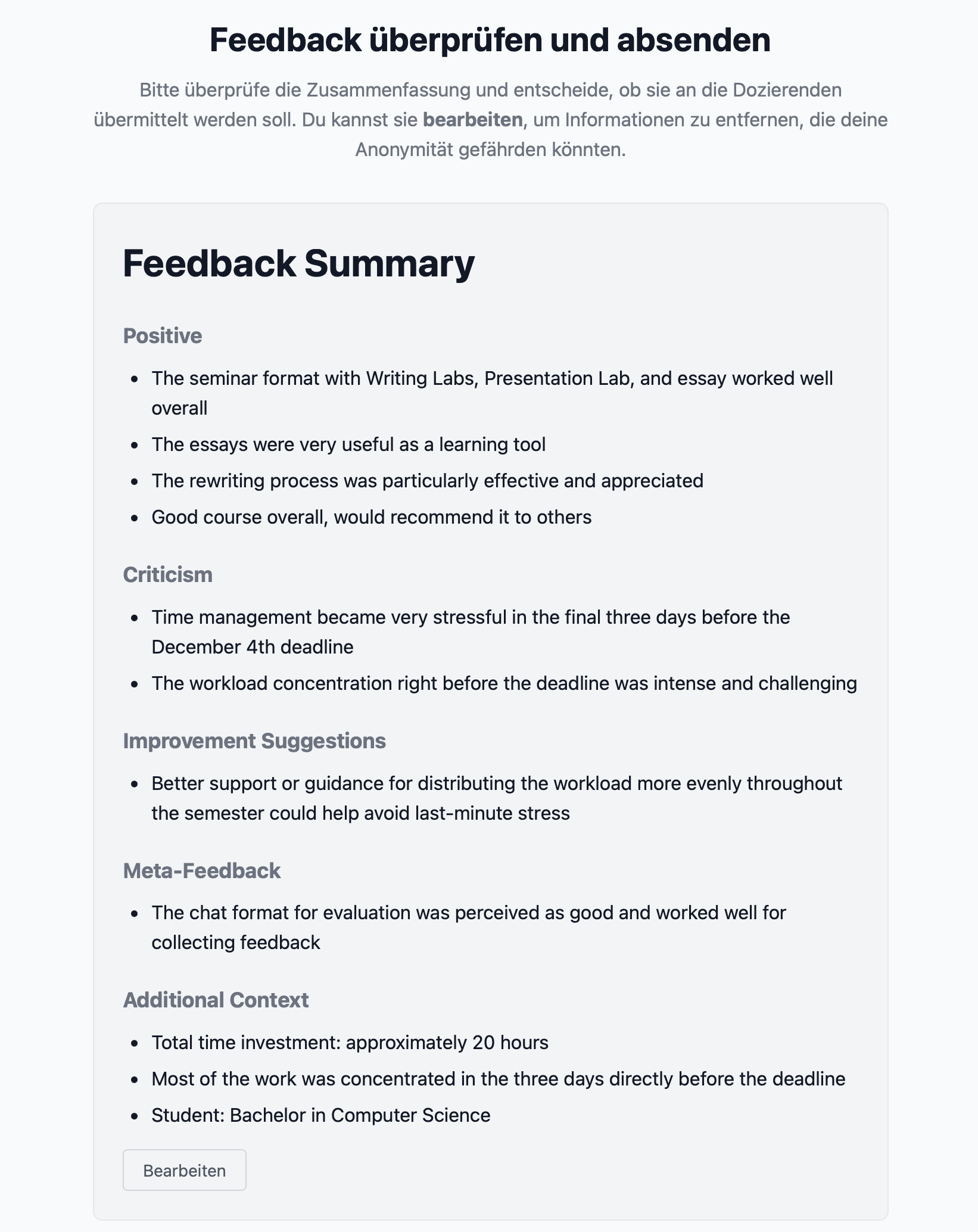 Studierende sehen die Summary in Markdown, gegliedert in Positiv · Kritik · Verbesserungsvorschläge · Meta-Feedback · Additional Context. Ein „Bearbeiten“-Button öffnet einen Edit-Modus; jede Änderung wird vermerkt, bevor aktiv freigegeben wird.
Studierende sehen die Summary in Markdown, gegliedert in Positiv · Kritik · Verbesserungsvorschläge · Meta-Feedback · Additional Context. Ein „Bearbeiten“-Button öffnet einen Edit-Modus; jede Änderung wird vermerkt, bevor aktiv freigegeben wird.
 Zwei klare Optionen: „Zusammenfassung übermitteln“ oder „Abbrechen und alles löschen“. Beim Abbrechen verschwinden sowohl Gesprächsverlauf als auch Zusammenfassung – nichts wird gespeichert, nichts übermittelt. Diese Symmetrie ist Kern der Freiwilligkeitszusage.
Zwei klare Optionen: „Zusammenfassung übermitteln“ oder „Abbrechen und alles löschen“. Beim Abbrechen verschwinden sowohl Gesprächsverlauf als auch Zusammenfassung – nichts wird gespeichert, nichts übermittelt. Diese Symmetrie ist Kern der Freiwilligkeitszusage.
Datenschutz in Kurz: Teilnahme freiwillig, Lehrende sehen keine Einzelchats, sondern nur die freigegebene Summary. Der Anwendungsserver läuft als VM an der Universität Bamberg, die LLM-Verarbeitung erfolgt über OpenRouter (USA) mit Zero-Data-Retention bei den Modell-Providern (Google Cloud, AWS); kein Modelltraining, Drittlandtransfer über Standardvertragsklauseln nach Art. 46 DSGVO. Speicherdauer: bis 90 Tage nach Befragungsende; Logs 7 Tage.
Das Begleitexperiment
Im Wintersemester 25/26 haben wir in der Vorlesung „Einführung in die Informatik“ drei verschiedene Feedback-Formate randomisiert verglichen. Studierende, die teilnehmen wollten, wurden per Zufall einer von drei Bedingungen zugeteilt – sie wussten erst beim Start, welche sie bekommen:
- Bedingung A – KI generisch: Der Bot kennt den Kurs nicht und fragt anhand allgemeiner Evaluationsdimensionen.
- Bedingung B – KI kontextualisiert: Derselbe Bot, aber mit Kurskontext (Wochenthemen, Übungen, Prüfungsformat).
- Bedingung C – Tutor:in: Ein menschlicher Tutor führt das Gespräch naturalistisch, mit demselben Kurs-Briefing.
Die Leitfrage war praktisch, nicht grundlagenwissenschaftlich: Lohnt sich ein kontextualisiertes Chat-Redesign gegenüber einer LLM-Übersetzung von EvaSys-Dimensionen – und wie schneidet beides gegen ein menschliches Tutor-Gespräch ab? Statt einen Einzelfaktor zu isolieren, haben wir drei Gesamtpakete verglichen, wie sie eine Hochschule praktisch einsetzen würde. Diese Designentscheidung hat einen Preis: Wenn das kontextualisierte System gewinnt, wissen wir nicht, ob es am Kurskontext, an proaktiver Themenführung oder an episodenbasierter Verankerung liegt; aber wir wissen, dass sich das Gesamtpaket lohnt.
Am Ende standen 62 vollständige Gespräche zur Auswertung – 20 in „KI generisch“, 21 in „KI spezifisch“, 20 in „Tutor“ (eine Tutor-Sitzung ohne verwertbaren Inhalt). Das ist eine explorative Pilotstudie, keine konfirmatorische: n≈20 erlaubt zuverlässig nur die Detektion großer Effekte. Berichtet werden in dieser Sondierung deskriptive Mittelwerte; das saubere Reporting folgt im Paper.
Vorläufige Befunde
Befund 1 – Dialogische Formate funktionieren grundsätzlich, alle drei. Auf den vier Likert-Items zu Ehrlichkeit, Kritik-Bereitschaft, Format-Angemessenheit und Weiterempfehlung liegen alle Bedingungen über 5,7 von 7. Wenn dialogische Formate alle hoch bewertet werden, ist die Hauptkonkurrenz nicht „eines der Formate“ gegen „ein anderes“, sondern dialogisch gegen Fragebogen-Status-Quo.
Befund 2 – Kurskontext zahlt sich messbar aus. Die kontextualisierte KI schneidet auf vier von vier Akzeptanz-Items besser ab als die generische:
| Item | KI generisch | KI spezifisch |
|---|---|---|
| Konnte Kritik äußern | 6.15 | 6.76 |
| Format war angenehm | 6.20 | 6.52 |
| Würde Format weiterempfehlen | 6.05 | 6.71 |
| Konnte ehrlich sein | 6.55 | 6.86 |
Die Effektstärken sind nicht riesig – 0,3 bis 0,6 Punkte auf einer 7-Punkte-Skala bei n=20–21. Aber sie zeigen konsistent in dieselbe Richtung. Die Investition in Kurskontext lohnt sich, jedenfalls in dieser Größenordnung.
Befund 3 – KI ist nicht der schwache Bruder. Auf den Items „Format war angenehm“ (5,80) und „Würde weiterempfehlen“ (5,75) liegt der Tutor sogar unter beiden KI-Bedingungen. Das war für uns die unerwartetste Beobachtung des Experiments, weil wir Tutor-Gespräche als bestmögliche Vergleichsbedingung eingeplant hatten. Möglicherweise spielt größere Varianz zwischen den Tutor:innen eine Rolle. Die Tutor-Sitzungen waren außerdem kürzer als die KI-Sessions (im Schnitt 29 vs. 33 vs. 37 Minuten). Pro Beitrag schreiben Studierende in allen drei Bedingungen ähnlich viel (ca. 32 Wörter), aber der Tutor stellt insgesamt weniger Fragen. Möglicher Trade-off: KI braucht mehr Zeit, liefert aber konsistenter.
Befund 4 – Studierende wollen es nochmal – vor allem die KI-Gruppe. Wer KI erlebt hat, würde mit 60 % wieder KI wählen. Wer Tutor erlebt hat, würde nur mit 35 % wieder Tutor wählen.
| Erlebt | Würde wieder KI wählen | Würde wieder Tutor wählen | „Egal“ |
|---|---|---|---|
| KI generisch | 60 % | 15 % | 10 % |
| KI spezifisch | 62 % | 5 % | 29 % |
| Tutor | 10 % | 35 % | 30 % |
Ein reiner Demand-Effekt (Höflichkeit gegenüber der erlebten Bedingung) erklärt diese Asymmetrie nicht: Die KI-Gruppe ist mit 60 % klar pro KI, die Tutor-Gruppe aber nur mit 35 % pro Tutor und gewichtet Fragebogen und „egal“ zusammen höher als ihre eigene Bedingung. Die KI-Erfahrung konvertiert offenbar stärker als die Tutor-Erfahrung – mögliche Gründe: weniger sozialer Druck, mehr Anonymität, weniger Wartezeit, niedrigere Erwartung an einen Bot, die dann übererfüllt wird.
Befund 5 – Was in den Summaries landet (und was nicht). Die kontextualisierte KI produziert im Mittel ca. 333 Summary-Wörter, die generische KI ca. 260, der Tutor ca. 191. Die Studierenden-Beiträge selbst sind aber pro Turn fast identisch ca. 32 Wörter lang; die Mengenunterschiede entstehen also über die Turn-Zahl, nicht über tiefere Antworten. Beim Tutor expandiert das Summary-LLM auf das 5-fache des User-Inputs (KI nur 2×), was zur höheren Edit-Distance bei Tutor-Summaries passt: Das Modell muss mehr glätten und ergänzen. Die Hypothese „generischer Bot = generischere Summary“ trägt nur schwach – Studierende bringen die Kursspezifika oft von sich aus mit. Der Unterschied liegt eher in der Verankerungstiefe: B-Summaries enthalten Wochennummern, Werknamen und Verzahnungen mit Parallel-Modulen, die ein generischer Bot nicht aufgreifen kann.
Befund 6 – Sozialer Druck taucht nur in der Tutor-Bedingung auf. Am Ende jedes Chats haben wir gefragt: „Wie war es für dich, das Gespräch zu führen?“ 61 Freitexte zeigen ein konsistentes Muster:
| Bedingung | Tonalität | Leitvokabular |
|---|---|---|
| KI generisch | sachlich-funktional | „neutral“, „effizient“, „schnell“, „wie ein Fragebogen“ |
| KI kontextualisiert | affektiv-entlastend | „kein Druck“, „anonym“, „unbefangen“, „nicht verurteilt“ |
| Tutor:in | gespalten | eine Hälfte „verstanden“, „angenehm“; die andere Hälfte „stressig“, „Sorge zu stören“, „Bewertungsangst“ |
Sozialer Druck wird in den beiden KI-Bedingungen null mal thematisiert, in der Tutor-Bedingung dafür mehrfach – Originalzitate: „Stressig, da man das Gefühl hat das jemand auf der anderen Seite warten muss.“ · „Es ist schwer, 3–4 Minuten lang nichts zu sagen, wenn man einen echten Menschen vor sich hat!“ Das ist die qualitative Erklärung für Befund 3: Es sind nicht die einzelnen schlechten Tutor:innen, es ist die soziale Situation selbst.
Die KI-Studierenden kritisieren weniger, als wir erwartet hatten. Floskelhaftigkeit oder „AI Slop“-Aversion werden nicht als Probleme benannt. Die einzige substantielle KI-Kritik ist ein Bias-Verdacht aus der generischen Bedingung: „die KI fühlt sich nicht neutral an, sondern als wäre sie mit der Meinung des Profs geprompted“. Eine Stimme, aber eine laute – im Prompt stand explizit, dass das Modell die Aussagen der Studierenden nicht werten soll. Eine durchgängig akzeptierende Haltung könnte mit „die Auswertung steht schon fest“ verwechselt werden; das ist für den produktiven Einsatz zu adressieren.
Wie die Live-Selbstevaluation lief
Im Mittelteil haben die Teilnehmenden 10 Minuten lang evalchat selbst ausprobiert – und zwar so, dass sie damit den laufenden Workshop bewerteten. Über einen für den Workshop angelegten Demo-Kurs öffneten sie evalchat, in dem der Bot per initial_message die Aufgabe „Bewerte den heutigen Workshop bis hierhin“ stellte. Von den anwesenden Personen haben elf das Gespräch bis zur Summary geführt und übermittelt. Diese elf Summaries sind die Grundlage für die aggregierte Auswertung weiter unten – einzelne Summaries oder wörtliche Auszüge reproduzieren wir bewusst nicht.
Was diskutiert wurde
Im 45-Minuten-Diskussionsteil und im parallel laufenden Pad kamen sechs Themen mehrfach zur Sprache.
Cluster 1 – Anwendungspotenziale jenseits klassischer Lehrevaluation. Mehrere Teilnehmende sehen einen klaren Einsatzbereich in der Weiterentwicklung neuer Lehrformate, nicht primär als EvaSys-Ersatz. Genannt wurden Seminare zur Bildungsmessung, Probeläufe mit Studierenden zur Format-Reflexion und Einsätze in kleineren Veranstaltungen mit experimentellem Charakter. Aufgekommen ist auch die Frage, wie sich dialogisches Feedback in formellen Kontexten unterbringen lässt – etwa als Bestandteil von Bewerbungsunterlagen für Habilstellen.
Cluster 2 – Vergleichbare Kennzahlen und Lesbarkeit für Dozierende. Der substanziellste Kritikpunkt – und der gleichzeitig auch in der KI-Auswertung der Selbst-Evaluationen ganz oben landete. Zwei verwandte, aber unterschiedliche Sorgen wurden in der Diskussion verschmolzen vorgebracht. Sorge 1 – fehlende Vergleichbarkeit über Likert-Anker. EvaSys liefert pro Veranstaltung Globalindikatoren und Skalenmittelwerte, die zwischen Kursen und Semestern vergleichbar sind und sich in formale Unterlagen einfügen lassen. Ein Chat-System produziert per Konstruktion solche Kennzahlen nicht. Wenn Vergleichbarkeit zwingend ist, braucht es entweder ein Nebeneinander mit einem Minimal-Fragebogen oder eine bewusst konstruierte LLM-basierte Skalierung mit klar markierten Limitationen. Sorge 2 – die Leselast bei vielen Summaries. Bei 100 abgegebenen Summaries sind 100 Markdown-Dokumente kein nutzbares Material. evalchat hat eine „Summaries verdichten“-Funktion, die genau dieses Problem adressiert – sie wurde im Workshop allerdings erst ganz am Ende kurz gezeigt. Das ist ein Vermittlungs-Befund über den Workshop selbst: Wenn eine Kernfunktion erst nach der entscheidenden Diskussionsphase auf den Tisch kommt, kann das Plenum sie nicht in seine Bewertung einfließen lassen.
Cluster 3 – Wann evaluieren? Semesterende ist zu spät. Wiederkehrende Beobachtung: Die großen Fragebögen kommen zu spät, um im laufenden Semester noch zu wirken. evalchat wäre formativ einsetzbar – die Konfiguration ist nur eine Frage des System-Prompts. Diskutiert wurde der Trade-off zwischen formativ und summativ: Formative Erhebungen brauchen eine Reaktionsschleife (Dozierende müssen antworten, was sie ändern), sonst entsteht Frustration. Mehrere Teilnehmende sehen darin den eigentlichen Hebel, der Lehrevaluation aus der Pflichtkür-Logik holt.
Cluster 4 – Diskussion mit Studierenden über die Auswertung. Der wertvollste Teil von Evaluation ist die Nachbesprechung im Kurs – evalchat-Summaries eignen sich dafür besser als EvaSys-Verbatims. Lehrende, die EvaSys-Auswertungen im Kurs nicht zeigen wollen, nannten den Grund: Verbatim-Statements sind nicht zur 1:1-Veröffentlichung freigegeben. evalchat-Summaries sind inhaltlich näher an dem, was Studierende sagen wollten, aber eben Zusammenfassungen statt O-Töne. Gleichzeitig wurde auf §27 (1) der Bamberger Evaluationsordnung verwiesen, die eine Pflicht zur Rückmeldung der aggregierten Ergebnisse an die Befragten festschreibt – formal über die Aggregat-Auswertung erfüllbar, in der Praxis aber selten gelebt.
Cluster 5 – Tutor-Validität und Format-Asymmetrie. Kritische Frage zum Experiment-Design: Ist der Tutor-Vergleich überhaupt fair, wenn die eigentliche Stärke von Tutor:innen das Gespräch ist – und nicht das Chatten? Die Tutor:innen im Experiment waren gebrieft, aber Menschen mit unterschiedlicher Chat-Affinität. Wenn künftig Chat-basierte Tutor-Evaluation Standard würde, gäbe es genau diese Streuung. Mehrfach geäußert wurde außerdem die Sorge, dass evalchat das Lernziel „kollegiales Feedback geben“ untergräbt: Wenn Studierende KI-Feedback bequemer finden, üben sie nicht mehr das schwierige direkte Gespräch. Eine pädagogische Frage, die der Baustein 2029 explizit adressieren muss.
Cluster 6 – Datenschutz und Drittlandtransfer. Die zentralen Klarstellungen: evalchat nutzt Claude nicht direkt über Anthropic, sondern über OpenRouter als Proxy, so konfiguriert, dass Anfragen nur an Modell-Provider mit Zero-Data-Retention-Zusage gerouted werden (Google Cloud, AWS). Eingaben werden nicht aufbewahrt und nicht für Modelltraining verwendet. Die Verarbeitung findet trotzdem in den USA statt – wir stützen uns auf Standardvertragsklauseln nach Art. 46 DSGVO, Behördenzugriff im Drittland lässt sich nicht vollständig ausschließen. Self-hosted Modelle (Llama, Mistral, Qwen) sind technisch möglich; die Qualität ist nach derzeitigem Stand deutlich niedriger. Für den Baustein 2029 sollte diese Frage explizit gemacht werden, inklusive eines Zeitplans, ab wann self-hosted ggf. tragfähig wird.
Aus den Pad-Notizen blieben außerdem einzelne Punkte stehen, die in den Cluster-Verdichtungen nicht aufgehen: Voice-Input als niedrigschwellige Alternative zum Tippen (mit Datenschutz-Vorbehalt), das Zurücksenden der Summary an die feedbackgebende Person, der Hinweis auf doppelte Fragen („was war angenehm UND was war störend?“), eine hybride Variante aus Formularfeldern mit LLM-Nachfrage sowie der Vorschlag einer klassischen Eval mit Fokus auf ein einzelnes Freitext-Item wie „Was war das größte Aha-Erlebnis?“.
Was die Meta-Auswertung sagt
Elf Teilnehmer:innen haben den Workshop per evalchat selbst evaluiert und ihre Summaries freigegeben. Die in evalchat eingebaute Verdichtungs-Funktion hat aus diesen elf Summaries einen aggregierten Bericht erstellt. Diese Schicht ist eine Demonstration der Verdichtungs-Funktion, kein Auswertungs-Standard: n=11 ist klein, die Verdichtung lief mit einem einzelnen LLM ohne Inter-Rater-Vergleich, und die Teilnehmenden waren ein selbstselektiertes Sample. Die Befunde sind also Hinweise, keine validen Aussagen.
 Pro Lehrveranstaltung verdichtet evalchat die freigegebenen Summaries zu „Top Positiv-Aspekten“, „Top Kritikpunkten“, „Verbesserungsvorschlägen“ und einer Muster-Analyse. Die Felder sind editierbar; eine Kompakt-Variante für formale Unterlagen ließe sich ableiten, ist aber noch nicht ausgebaut.
Pro Lehrveranstaltung verdichtet evalchat die freigegebenen Summaries zu „Top Positiv-Aspekten“, „Top Kritikpunkten“, „Verbesserungsvorschlägen“ und einer Muster-Analyse. Die Felder sind editierbar; eine Kompakt-Variante für formale Unterlagen ließe sich ableiten, ist aber noch nicht ausgebaut.
Top-Positiv-Aspekte. Live-Demo und Hands-on stehen mit Abstand vorn (8 von 11): Erst das eigene Ausprobieren machte das Format greifbar. Daneben werden Verständlichkeit und Tempo des Input-Blocks, die Befunde aus dem Begleitexperiment (besonders Befund 3, 4 und 6), das Chat-Format als Evaluationsmethode, die Anwendbarkeit für eigene Kontexte und das Session-Format insgesamt wiederholt gelobt.
Top-Kritikpunkte. Die Kritik ist konsistent und auffällig stärker auf Produktreife als auf Workshop-Inhalte gerichtet: fehlende vergleichbare Kennzahlen und Lese-Last (Cluster 2); die strukturierte Chat-Führung als Korsett (3 Nennungen) – der Bot setzt Themen, statt sie offen kommen zu lassen; unklarer Nutzen für Dozierende und fehlende Einbettung in Qualitätsentwicklung über mehrere Semester; Länge und Format-Präferenzen (Input-Block an der Längengrenze, 90 Minuten für einzelne zu lang); Einprägsamkeit der Befunde mit Erinnerungslücken bei Details; Bedenken zu KI versus menschlichem Dialog im Sinne von Cluster 5.
Top-Verbesserungsvorschläge. Die Vorschläge liegen mehrheitlich auf Produktebene, nicht auf Workshop-Ebene – das ist das eigentliche Ergebnis dieser Selbstevaluation: eine LLM-basierte Skalenmetrik mit ehrlichen Limitationen prüfen und die Summaries-Verdichtung in Sondierungs-Formaten vor der Hands-on-Phase zeigen; Voice-Input ergänzen; Balance zwischen Struktur und Offenheit optimieren; Dozierenden-Perspektive sichtbarer integrieren; weniger defensive Einordnung in der Präsentation; praktische Zusatzfunktionen wie Folien-Download.
Vier Muster, die für die Baustein-Konzeption 2029 wichtig sind. Erstens eine bimodale Verteilung bei Format-Präferenzen – 6 Teilnehmende bewerteten das Chat-Format als besser als Fragebögen, 2 als weniger zielführend; ein Nebeneinander ist sinnvoller als ein Entweder-Oder. Zweitens Begeisterung für Befunde versus Erinnerungslücken – emotionale Resonanz bei gleichzeitiger kognitiver Überladung; eine kürzere Befund-Sequenz mit weniger Detail würde wahrscheinlich besser haften. Drittens eine systematische Lücke bei Vergleichbarkeit und Praxistauglichkeit – die kritischste Lücke ist nicht das Format selbst, sondern seine institutionelle Einbettung. Viertens Sozialer Druck als zentrales Erkenntnisthema – offene Meta-Frage: Ist die richtige Antwort darauf technisch (KI wegnehmen) oder pädagogisch (psychologische Sicherheit schaffen)? Beide Wege haben Vor- und Nachteile, und sie sind nicht exklusiv.
Was wir mitnehmen
Aus der Session und der Meta-Auswertung kristallisieren sich drei Prioritäten heraus, die mit dem nächsten Schritt am evalchat-Prototyp und mit dem Baustein 2029 verbunden sind.
Priorität 1 – Vergleichbarkeit ohne Etikettenschwindel. Die Summary-Verdichtung ist vorhanden und löst die Lese-Last bei vielen Einzel-Summaries. Was fehlt, ist eine konstruktiv ehrliche Antwort auf den Wunsch nach Skalenwerten – entweder ein klar abgegrenzter Minimal-Fragebogen-Aufsatz oder eine LLM-basierte Skalierung mit explizit ausgewiesenen Limitationen, plus Trend-Vergleich über Semester und Kompakt-Export für formale Unterlagen.
Priorität 2 – Dozierenden-Perspektive sichtbar machen. Was sieht eine Lehrperson nach Abschluss einer Erhebung – im Detail, im Verlauf, mit welcher Reaktions-Erwartung? Diese Sicht war im Workshop unterbelichtet und gehört nach vorn.
Priorität 3 – Formativ-Spektrum entwickeln. evalchat ist heute auf End-of-term-Erhebungen optimiert, lässt sich aber mit minimalem Aufwand auf semesterbegleitende Formate umkonfigurieren. Voraussetzung für Wirksamkeit ist eine Antwort-Schleife zurück an die Studierenden – nicht nur Erhebung.
Die wichtigste Erkenntnis aus dieser Sondierung ist nicht das Lob, sondern die bimodale Verteilung. Ein Teil des Plenums sieht evalchat als überfällige Ergänzung; ein anderer Teil bleibt skeptisch gegenüber KI-vermittelter Lehrevaluation oder hält klassische Frontalformate für effizienter. Der Baustein 2029 sollte nicht versuchen, diese Spannung aufzulösen, sondern sie als Konstruktionsprinzip aufnehmen: ein Nebeneinander von Formaten, in dem evalchat eine Option ist – nicht der Standard, nicht der Ersatz. Gleichzeitig wiegt die in Cluster 5 genannte Sorge ernst, dass dialogische KI-Evaluation die Kompetenz zum direkten kollegialen Feedback erodiert: Wo trainiert die Hochschule die Fähigkeit zum unbeholfen-direkten Feedback weiter, wenn evalchat einen Teil der entlastenden Funktion übernimmt?
Weiterführend
- Ankündigung und Hintergrund zur Session: Open Session „evalchat – Eine Feedback-App als Alternative zur Lehrevaluation“
- Verwandter Bericht: Open Session „E-Prüfungen mit psi-exam“
- Kontakt für Mitwirkung als Pilot-Lehrende:r, Tester:in oder Reviewer:in der Baustein-Konzeption: dh.psi@uni-bamberg.de